Google veröffentlicht Gemini 3.1 Flash-Lite: Effizienter KI-Baustein für großskalige Produktivsysteme
Lesezeit: ca. 8 Minuten
Key Takeaways
- Google stellt mit Gemini 3.1 Flash-Lite das bislang kostengünstigste Modell der Gemini 3-Serie vor.
- Flash-Lite ist speziell auf Aufgaben mit hohem Volumen optimiert, bei denen niedrige Latenz und ein geringer Kosten-pro-Token-Wert im Fokus stehen.
- Das Modell steht ab sofort in der Public Preview im Gemini API (Google AI Studio) sowie über Vertex AI zur Verfügung.
- Flash-Lite ist für eine breite Skalierbarkeit im Produktionsumfeld („intelligence at scale“) ausgelegt.
- Die Möglichkeit, verschiedene Denk-Niveaus („adjustable thinking levels“) einzustellen, steigert die Flexibilität für Entwickler und Unternehmen.
Einordnung: Gemini 3.1 Flash-Lite im Überblick
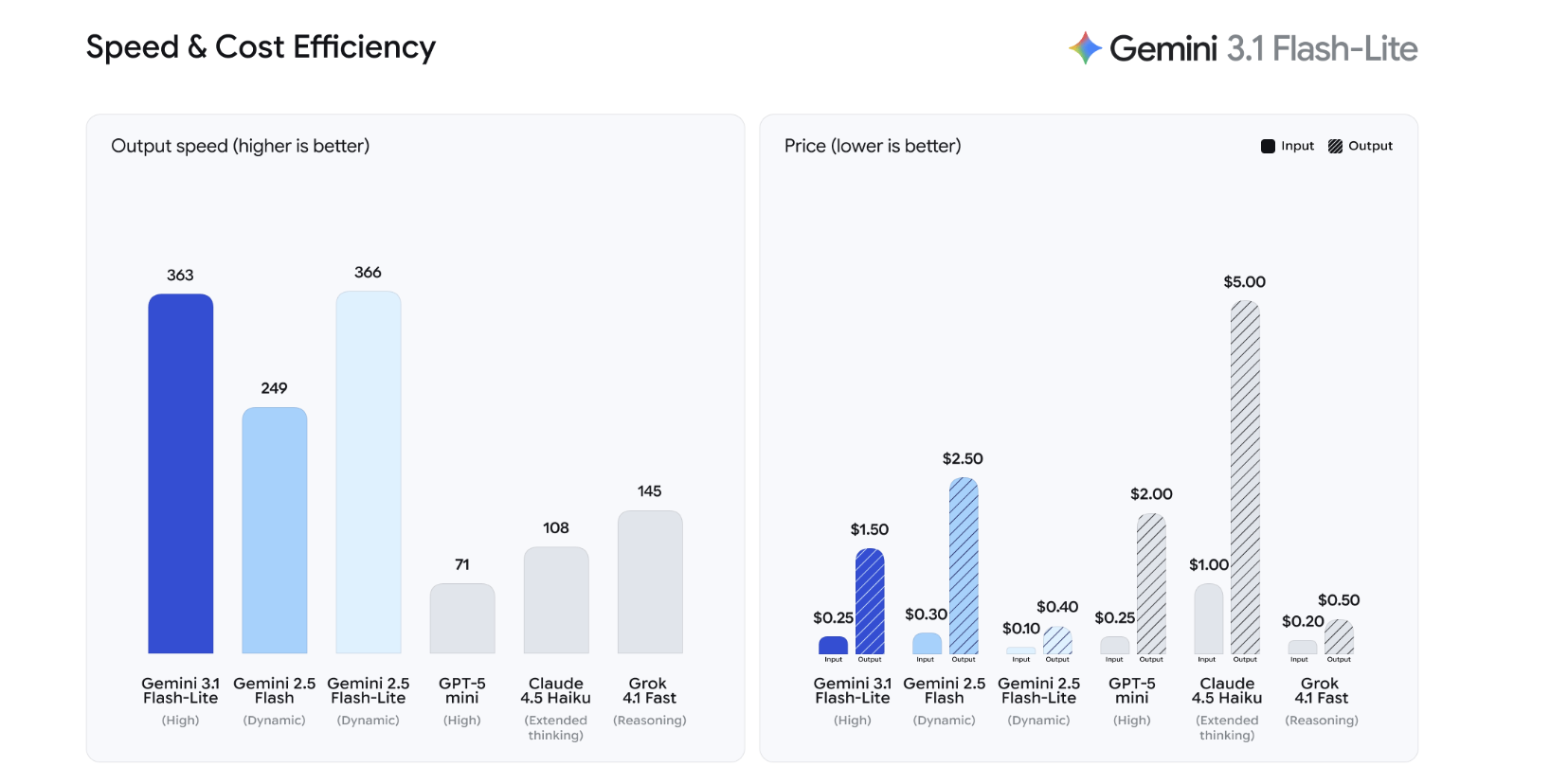
Google erweitert mit Gemini 3.1 Flash-Lite sein Modell-Portfolio um eine besonders effiziente und kostengünstige Variante. Laut offiziellen Angaben ist Flash-Lite das am stärksten auf Wirtschaftlichkeit getrimmte Modell der Gemini 3 Series. Der Fokus liegt ganz klar auf Anwendungen, die in großem Maßstab ausgeführt werden müssen – etwa der Einsatz in Produktivumgebungen großer Unternehmen, massenhaft ausgelöste API-Calls oder die Integration in skalierende Dienste, bei denen jedes zusätzliche Token ins Gewicht fällt.
Kernmerkmale von Gemini 3.1 Flash-Lite
Im Vordergrund von Flash-Lite stehen zwei technische Ziele: geringe Latenz und niedrige Kosten pro Token. Das Modell ist für hohe Abfragevolumina gebaut und lässt sich nahtlos in bestehende Google-Dienste wie die Gemini API im Google AI Studio sowie Vertex AI integrieren.
Mit Flash-Lite macht Google ein Angebot an all jene, die KI vor allem unter Skalierungsbedingungen denken: Der Algorithmus ist auf Effizienz getrimmt, etwa durch optimiertes Modell-Design und Bodenständigkeit im Ressourcenverbrauch. Komponenten wie adjustable thinking levels erhöhen dabei die Kontrollierbarkeit je nach Anwendungsbedarf.
Intelligenz auf Skala: Produktions-KI mit Flash-Lite
Produktivitäts- oder Massen-Anwendungen wie Customer Support, Echtzeit-Analyse, Monitoring oder automatische Textbearbeitung stellen spezielle Anforderungen an KI-Modelle. Sie müssen nicht immer maximal kreativ oder besonders elaboriert antworten, sondern vor allem schnell und kostengünstig Ergebnisse liefern. Die Gemini 3.1 Flash-Lite-Variante ist dafür konzipiert, genau diese Aufgabenstellungen effizient und stabil umzusetzen.
Durch die Public Preview in Gemini API und Vertex AI ist Flash-Lite unmittelbar für Entwickler und Unternehmen verfügbar, die bereits Google Cloud-Services nutzen und schnell skalieren möchten. Gerade bei Projekte mit Tausenden oder sogar Millionen von API-Abfragen amortisieren sich die Einsparpotenziale besonders deutlich.
Technische Besonderheiten und typische Anwendungsfälle
Der entscheidende technische Vorteil von Flash-Lite liegt in seinem Fokus auf „latency and cost-per-token optimization“. Das Modell kann flexibel in High Scale-Szenarien positioniert werden – etwa in Chatbots mit hohem Volumen, im Bulk-Processing von Inhalten, bei der Automatisierung von Geschäftsabläufen oder beim Ausbau datengetriebener Workflows.
Mit den adjustable thinking levels sind Entwickler zudem in der Lage, die Modellantworten noch stärker nach eigenen Kriterien zu steuern: Je nach Anwendungszweck kann das Antwortverhalten von besonders einfach (weniger Tiefgang, weniger Kosten) bis hin zu ausführlicher/umfangreicher eingestellt werden – immer mit dem Ziel, Kosten und Tempo optimal auszubalancieren.
Verfügbarkeit und Integration in bestehende Infrastruktur
Gemini 3.1 Flash-Lite ist ab dem 03. März 2026 im Google AI Studio über die Gemini API sowie auf Vertex AI verfügbar – zunächst im Public Preview-Modus. Damit erhalten Unternehmen und Entwickler schnellen Zugang, um ihre Lösungen zu testen und sukzessive zu operationalisieren.
Gerade durch die Anbindung an Standardplattformen wie Vertex AI integriert sich Flash-Lite mühelos in bestehende Workflows und kann schrittweise in produktiven Umgebungen ausgerollt werden.
Fazit: Vielseitiges Modell für skalierbare KI-Produktivität
Mit Gemini 3.1 Flash-Lite legt Google den Fokus auf die Optimierung von KI-Anwendungen für Geschwindigkeit und Kosten. Für Entwickler, Tech-Teams und Unternehmen, die KI-Lösungen auf Produktionsniveau skalieren wollen und dabei Wirtschaftlichkeit im Blick behalten müssen, eröffnet Flash-Lite neue Spielräume. Die Möglichkeit, Anpassungen bei den Denk-Niveaus vorzunehmen, sorgt für ein flexibles Gleichgewicht zwischen Qualitätsanspruch und Skalierbarkeit.
Wer auf Google AI Studio oder Vertex AI setzt, kann Flash-Lite ab sofort ausprobieren und für eigene Use Cases evaluieren.
Bildquelle: https://www.marktechpost.com/2026/03/03/google-drops-gemini-3-1-flash-lite-a-cost-efficient-powerhouse-with-adjustable-thinking-levels-designed-for-high-scale-production-ai/
What do you feel about this post?

Like

Love

Happy

Haha

Sad