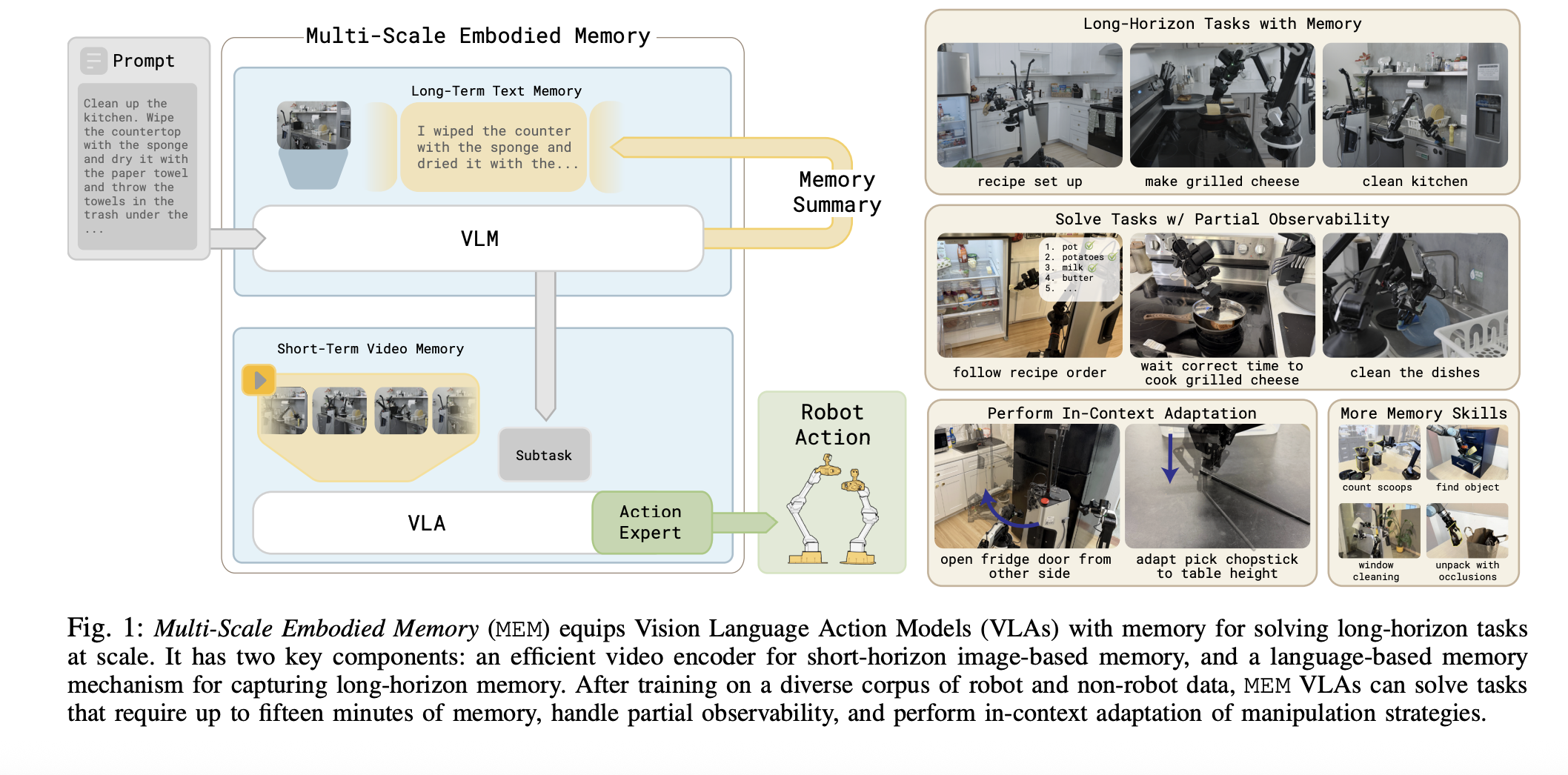
Physical Intelligence Team präsentiert MEM: Multi-Skalen-Memory für Gemma 3-4B VLAs ermöglicht 15-minütigen Kontext für komplexe Aufgaben
Lesezeit: ca. 12 Minuten
Key Takeaways
- Aktuelle Vision-Language-Action (VLA) Modelle arbeiten meist nur mit einzelnen Beobachtungen oder sehr kurzer Historie und sind damit für komplexe Aufgaben limitiert.
- Das Forschungsteam von Physical Intelligence, Stanford, UC Berkeley und MIT adressiert diese Limitierung mit einem neuen Multi-Skalen-Memory-System (MEM).
- MEM erweitert Gemma 3-4B VLA-Modelle um einen 15-minütigen Kontext und erleichtert damit langanhaltende robotische Aufgaben wie Küchenputzen oder komplexe Anleitungen.
- Die Lösung zielt auf praktische Verbesserungen in der Robustheit und Zuverlässigkeit von KI-gesteuerten Robotersystemen ab.
- Weitere Details unter: MarkTechPost
Hintergrund und Problematik aktueller VLA-Modelle
Vision-Language-Action Modelle verbinden visuelle Daten mit Sprachverständnis und Steuerbefehlen, um Roboter klassischerweise in dynamischen Alltagssituationen einsetzbar zu machen. Der technologische Kern: Die Entscheidungsfindung erfolgt auf Basis der aktuellen Aufnahme oder eines extrem kurzen Rückblicks auf vorangegangene Aktionen – meist wenige Sekunden oder einzelne Frames.
Die Konsequenz ist gravierend: Sobald Roboter vor langanhaltende, komplexe Aufgaben wie das vollständige Aufräumen einer Küche, das Sortieren mehrerer Gegenstände oder das minutiöse Folgen einer Rezeptanleitung gestellt werden, geraten die Systeme an ihre Grenzen. Die fehlende Gedächtnisstruktur führt zu Fehlern, ineffizientem Ressourcenverbrauch und einer drastischen Erhöhung des Scheiterns bei realen Langzeitszenarien.
Innovationskern: Das Multi-Skalen-Memory-System (MEM)
Das Forschungskonsortium von Physical Intelligence, Stanford, UC Berkeley und MIT hat einen neuen Ansatz vorgestellt: das Multi-Scale Memory System (MEM). Dieses System hebt die KI-gestützte Robotik auf die nächste Evolutionsstufe, indem es den Kontext für Vision-Language-Action-Modelle signifikant erweitert.
Konkret integriert MEM sogenannte Multi-Skalen-Speicherstrukturen, die es dem Roboter erlauben, Beobachtungen, Sprachbefehle und relevanten Kontext über einen Zeitraum von bis zu 15 Minuten effektiv zu speichern, abzurufen und in aktuelle Entscheidungsprozesse einzubeziehen. Durch diese Fähigkeit lassen sich auch verschachtelte, mehrschrittige Aufgaben, die eine anhaltende Interaktionshistorie erfordern, wesentlich zuverlässiger umsetzen.
Anwendungsbeispiele und technische Umsetzung
MEM wurde für den Einsatz in Verbindung mit Gemma 3-4B VLA-Modellen optimiert. Die erweiterte Gedächtniskapazität bedeutet, dass der Roboter komplexe Aufgaben mit langem situativen Verlauf bewältigen kann – darunter die einzelnen Schritte beim Reinigen einer Küche samt Zwischenschritten, das systematische Finden und Sortieren von Gegenständen oder das exakte Verfolgen längerer Kochanleitungen.
Im Fokus steht dabei nicht allein das passive Erinnern von Bildern oder Befehlen. Vielmehr synchronisiert MEM verschiedene Informationsquellen – visuelle Inputs, Sprachverläufe und interne Status – und stellt diese in jedem Moment dynamisch für die Entscheidungsfindung bereit.
Der große Vorteil: Aufgaben lassen sich nicht nur kontinuierlicher und sicherer durchführen, sondern auch Missverständnisse durch verlorenen Kontext – etwa das Vergessen eines bereits erledigten Schritts – werden minimiert.
Aktuelle VLA-Modelle agieren fast kontextfrei – MEM verwandelt sie in lernende, erinnerungsfähige Akteure für reale Umgebungen.
Vorteile für robotische Anwendungen
- Langzeiterinnerung ermöglicht strategische Planung und Wiedererkennung über viele Sequenzen hinweg.
- Fehlerreduktion durch Speicherung abgeschlossener Teilschritte und Redundanzvermeidung.
- Komplexitätsbeherrschung für Aufgaben, die mehrere Subziele und Interaktionen erfordern.
- Robustere Steuerung auch bei Unterbrechungen oder unerwarteten Umgebungsveränderungen.
Bewertung und Ausblick
MEM stellt einen entscheidenden Schritt dar, um KI-gesteuerte Roboter von rein reaktiven, kurzzeitgedächtnisbasierten Werkzeugen zu autonomen, lernfähigen Alltagshelfern weiterzuentwickeln. Der Ansatz bündelt Expertise aus mehreren renommierten Forschungseinrichtungen und fokussiert sich auf nachvollziehbare, anwendungsnahe Probleme.
Indem der Kontext für VLAs von wenigen Sekunden auf eine Viertelstunde angehoben wird, verändert sich die Spanne der realisierbaren Aufgaben grundlegend. Dadurch könnten neue Maßstäbe für Service-Robotik in Haushalten, Industrie und öffentlichen Räumen gesetzt werden.
Weitere Einzelheiten und Originaldetails finden sich direkt bei MarkTechPost.
Fazit & Ausblick
Das Multi-Scale Memory System (MEM) adressiert eine der zentralen Schwächen bisheriger KI-Robotik-Modelle: Das fehlende Langzeitgedächtnis. Durch die Integration dieser Speicherstrukturen gewinnen Vision-Language-Action-Modelle ein neues Qualitätsniveau für komplexe, praxistaugliche Anwendungen. Wer aktuelle Entwicklungen rund um KI, Robotik und VLA-Modelle weiterverfolgen will, sollte einen Blick auf die Originalpublikation bei MarkTechPost werfen.
Bildquelle: https://www.marktechpost.com/2026/03/03/physical-intelligence-team-unveils-mem-for-robots-a-multi-scale-memory-system-giving-gemma-3-4b-vlas-15-minute-context-for-complex-tasks/
What do you feel about this post?

Like

Love

Happy

Haha

Sad