Google DeepMind stellt Unified Latents (UL) vor: Neue ML-Framework zur gemeinsamen Regularisierung von Latents mit Diffusion Prior und Decoder
Lesezeit: ca. 10 Minuten
Key Takeaways
- Latente Diffusionsmodelle (LDMs) komprimieren hochdimensionale Daten in einen latenten Raum, um die Synthese großer Auflösungen effizienter zu gestalten.
- Es besteht ein grundlegender Zielkonflikt zwischen niedriger Informationsdichte (leichter zu lernen, geringere Rekonstruktionsqualität) und hoher Dichte (bessere Rekonstruktion, schwerer zu lernen).
- Google DeepMind hat das Framework „Unified Latents (UL)“ vorgestellt, das Latents gemeinsam mithilfe eines Diffusion Prior und Decoders regularisiert.
- Die Technik adressiert zentrale Herausforderungen aktueller generativer KI-Modelle hinsichtlich Rekonstruktionsqualität und Trainingseffizienz.
- Weitere Details und Informationen sind im Originalbeitrag auf MarkTechPost nachzulesen.
Hintergrund: Latent Diffusion Models (LDMs) und ihr Zielkonflikt
Generative KI hat sich in den letzten Jahren rasant weiterentwickelt. Einer der wichtigsten Fortschritte ist der Einsatz von Latent Diffusion Models (LDMs). Diese Modelle reduzieren den enormen Rechenaufwand, der bei der Synthese hochauflösender Daten entsteht, indem sie die eigentlichen Daten in einen sogenannten latenten Raum komprimieren. Die latenten Repräsentationen sind dabei weniger komplex und benötigen weniger Ressourcen als die Rohdaten selbst. Das Prinzip: Statt direkt auf hochdimensionalen Rohdaten (etwa hochauflösenden Bildern) zu arbeiten, wird ein kompakteres, informationsdichtes Abbild – der Latent – erzeugt. Dieser ermöglicht es, Modelle skalierbar zu trainieren und dennoch hochwertige Generierungsergebnisse zu erzeugen.
Das Problem der Informationsdichte im Latenten Raum
Der Erfolg der LDMs geht jedoch mit einem grundlegenden Zielkonflikt einher. Die Informationsdichte des latenten Raums beeinflusst maßgeblich die Performance der Diffusionsmodelle:
- Wird die Informationsdichte der latenten Repräsentation niedrig gewählt, ist das maschinelle Lernen zwar einfacher und die Trainingskosten sinken – doch leiden darunter die Detailtreue und Qualität der Rekonstruktion, weil wichtige Informationen verloren gehen.
- Umgekehrt erlaubt eine hohe Informationsdichte eine nahezu perfekte Rekonstruktion der Ausgangsdaten, erschwert aber das Training deutlich, weil der Lernaufwand im hochdimensionalen Raum steigt.
Diese binäre Struktur zwingt bisherige Diffusionsmodelle, stets einen Kompromiss zwischen Trainingsaufwand und Rekonstruktionsqualität einzugehen.
Google DeepMind Unified Latents: Ein neues Framework zur Lösung dieses Zielkonflikts
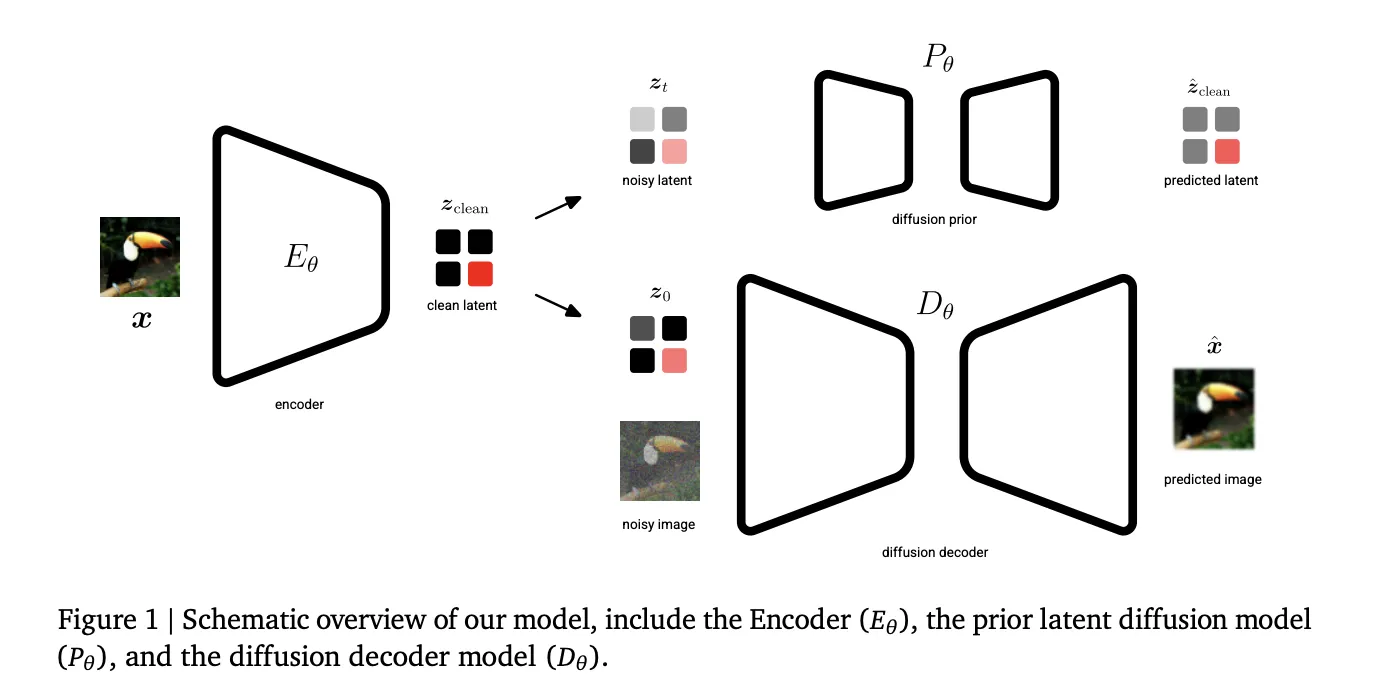
Um diesen Zielkonflikt anzugehen, hat Google DeepMind mit Unified Latents (UL) ein maschinelles Lern-Framework präsentiert, das einen neuartigen Ansatz verfolgt. Im Zentrum steht eine gemeinsame Regularisierung der latenten Repräsentation – und zwar sowohl mithilfe eines Diffusion Prior als auch eines Decoders. Mit diesem Ansatz werden die Vorteile beider Welten des latenten Raums – niedrige und hohe Informationsdichte – zu vereinen versucht.
Zentrale Konzepte der UL-Methode
- Diffusion Prior: Die latenten Codes werden durch einen Diffusionsprozess so geformt, dass sie sowohl effizient als auch repräsentativ für die Originaldaten sind.
- Decoder-Integration: Neben dem Diffusion Prior erfolgt eine zusätzliche Regularisierung direkt auf der Decodierungsebene. So wird die Rekonstruktionsqualität im Training durch den Decoder aktiv in die Optimierung einbezogen.
- Gleichzeitiger Abgleich: Statt beide Prozesse einzeln zu optimieren, werden sie beim Training gemeinsam betrachtet (joint regularization). Damit wird ein Gleichgewicht zwischen leichter Lernbarkeit und Rekonstruktionsstärke angestrebt.
Die Verbindung dieser beiden Regularisierungsstränge unterscheidet UL von klassischen LDMs, die meist stark auf die Optimierung eines einzelnen Schrittes angewiesen sind.
Bedeutung und Implikationen für die Entwicklung generativer KI
Durch die Verringerung des Abhängigkeit von Kompromissen profitieren künftig generative KI-Modelle von Unified Latents potenziell in mehreren zentralen Bereichen:
- Verbesserte Rekonstruktion hochaufgelöster Inhalte ohne exponentiell steigenden Rechenaufwand.
- Effizienteres Lernen latenter Repräsentationen, was sowohl das Training als auch das Fine-Tuning für verschiedene Aufgaben vereinfacht.
- Skalierbarkeit durch die gezielte Anpassung der Regularisierungskriterien an verschiedene Anwendungsgebiete.
- Neue Ansätze, um bisherige Limitationen (z. B. Artefakte oder Informationsverluste bei der Rückübersetzung von Latents in Rohdaten) anzugehen.
Weiterführende Informationen
Weitere Details zur Vorstellung und zu den zugrundeliegenden Methoden sind im Originalbeitrag auf MarkTechPost veröffentlicht.
Fazit: Fortschritt für generative KI durch Unified Latents
Das von Google DeepMind entwickelte Framework Unified Latents (UL) adressiert den zentralen Zielkonflikt bestehender Latent Diffusion Models: die Balance zwischen effizienter Lernbarkeit und hoher Rekonstruktionsqualität im latenten Raum. Durch die gemeinsame Regularisierung mit Diffusion Prior und Decoder eröffnet UL neue Möglichkeiten für künftige Entwicklungen in der generativen KI.
Für detaillierte technische Hintergründe und aktuelle Ergebnisse empfiehlt sich ein Blick auf den vollständigen Beitrag bei MarkTechPost.
Bildquelle: https://www.marktechpost.com/2026/02/27/google-deepmind-introduces-unified-latents-ul-a-machine-learning-framework-that-jointly-regularizes-latents-using-a-diffusion-prior-and-decoder/
What do you feel about this post?

Like

Love

Happy

Haha

Sad