NVIDIA AI veröffentlicht Nemotron-Terminal: Systematische Data-Engineering-Pipeline für das Skalieren von LLM-Terminal-Agenten
Lesezeit: ca. 9 Minuten
Key Takeaways
- Die Entwicklung autonomer AI-Agenten wird zunehmend durch begrenzte und schwer zugängliche Trainingsdaten gehemmt.
- Fortschrittliche Modelle wie Claude Code und Codex CLI zeigen beachtliche Fähigkeiten in Terminal-Umgebungen, ihre Trainingsdaten und Strategien jedoch bleiben proprietär und intransparent.
- NVIDIA AI geht mit der Veröffentlichung von Nemotron-Terminal einen neuen Weg, um mithilfe systematischer Data-Engineering-Pipelines die Entwicklung und Skalierung von LLM-basierten Terminal-Agenten voranzutreiben.
- Die fehlende Offenheit vieler Unternehmen zwingt Forschende und Entwickler zu ineffizienten, kostenintensiven Ansätzen im Datenzugang und Modelltraining.
- Der Ansatz von NVIDIA AI zielt darauf ab, diese Flaschenhälse gezielt zu adressieren und Transparenz sowie Effizienz bei der Skalierung von LLM-basierten Terminal-Agenten zu fördern.
Die Datenknappheit als Bremsklotz für autonome KI-Agenten
Führende KI-Entwickler arbeiten mit Hochdruck daran, autonome Agenten hervorzubringen, die auf Großsprachmodellen (LLMs) basieren und komplexe Aufgaben in unterschiedlichsten Umgebungen durchführen – beispielsweise als Assistenten in Terminal-Interfaces. Dabei stößt die Industrie auf ein zentrales Problem: Daten.
Während Modelle wie Claude Code und Codex CLI bereits hohe Kompetenz im Umgang mit Terminal-Befehlen und -Abläufen demonstrieren, sind Details zu ihren Trainingsdaten sowie deren Zusammenstellung und Feinabstimmung nicht öffentlich zugänglich. Die Trainingsstrategien dieser proprietären Modelle bleiben ein gut gehütetes Geschäftsgeheimnis.
Forschende und Entwickler stehen damit vor der Herausforderung, entweder teuer eigene Datensätze zu generieren oder iterative Experimente zu fahren, um vergleichbare Ergebnisse zu erzielen. Dieser Mangel an Transparenz schafft einen ineffizienten Silo-Effekt, der wertvolle Ressourcen bindet und die Innovationsgeschwindigkeit im KI-Bereich verlangsamt.
NVIDIA Nemotron-Terminal: Ein neuer Ansatz im Data Engineering
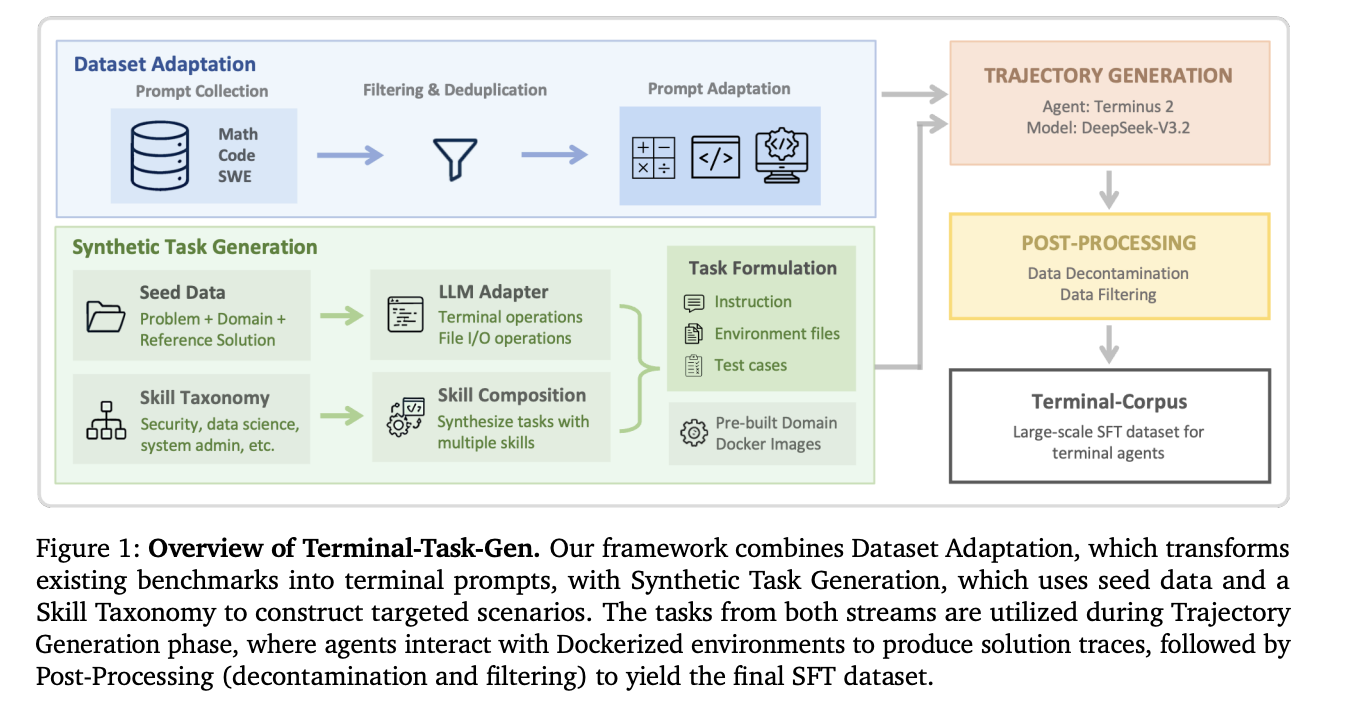
Vor diesem Hintergrund hat NVIDIA AI die Veröffentlichung von Nemotron-Terminal bekannt gegeben. Dabei handelt es sich um eine systematische Data-Engineering-Pipeline, die speziell dafür konzipiert wurde, den Engpass bei der Skalierung leistungsfähiger LLM-basierter Terminal-Agenten zu beheben.
Der Pipeline-Ansatz verfolgt das Ziel, den gesamten Lebenszyklus der Datenanalyse, -aufbereitung und -bereitstellung für das Training, Fine-Tuning und Testen von Large Language Models in terminalbasierten Anwendungsfällen methodisch abzubilden. Durch die systematische Struktur wird die Grundlage geschaffen, Trainingsdaten in größerem Umfang und mit höherer Reproduzierbarkeit bereitzustellen.
Systematische Datenpipeline: Aufbau und Nutzen
Im Zentrum von Nemotron-Terminal steht eine konsequent strukturierte Pipeline-Architektur. Der gesamte Prozess von der Datenbeschaffung über Vorverarbeitungsschritte bis hin zur automatisierten Annotation und Qualitätskontrolle wird dabei abgedeckt. Dies gewährleistet eine konsistente, skalierbare und nachvollziehbare Datenbasis für das Training von LLMs im Terminal-Kontext.
Zu den wichtigsten Vorteilen gehören:
- Automatisierte Datenakquise und -aufbereitung: Die Pipeline unterstützt bei der Extraktion relevanter Terminal-Interaktionen aus verschiedenen Quellen und bereitet diese für das Modelltraining auf.
- Strukturierte Annotation: Systematische Zuordnung von Kontext, Aufgabenbeschreibung und Zielvorgaben für einzelne Datensätze, um differenzierte und skalierbare Trainingssets zu ermöglichen.
- Qualitätsmanagement und Nachvollziehbarkeit: Jeder Datenpunkt in der Pipeline wird überprüft, nach einheitlichen Kriterien bewertet und dokumentiert.
- Optimierte Schnittstelle für LLM-Training: Das Endergebnis ist ein hochstrukturiertes, wiederverwendbares Daten-Repository, das für verschiedene LLM-Architekturen genutzt werden kann.
Nemotron-Terminal adressiert explizit das Problem der fehlenden Standardisierung in der Community. Die Pipeline ist darauf ausgelegt, Transparenz sowohl im Datenfluss als auch in der Anwendbarkeit für verschiedene ML-Projekte sicherzustellen.
Die Rolle von Datenmischungen und Trainingsstrategien
Die Qualität, Vielfalt und Relevanz der verwendeten Datenmischungen spielt eine entscheidende Rolle bei der Entwicklung fortschrittlicher LLMs für Terminal-Agenten. Proprietäre Modelle wie Claude Code und Codex CLI haben gezeigt, dass nicht nur die Quantität, sondern insbesondere die passgenaue Auswahl, Mischung und Gewichtung spezifischer Trainingsdaten über die Praxistauglichkeit des resultierenden Agenten bestimmt.
NVIDIA AI hebt in der Vorstellung von Nemotron-Terminal hervor, dass bisherige Intransparenz in Bezug auf diese Datenmischungen zu einem erheblichen Innovationsstau geführt hat. Mangels Einblicken müssen Entwickler bestehende Trainingsverfahren mehrfach und mit großem Ressourceneinsatz nachbauen – mit unterschiedlich erfolgreichen Resultaten.
Der systematische Pipeline-Ansatz von Nemotron-Terminal schafft einen geregelten Rahmen, in dem Datenquellen und -strukturen für das Training von Terminal-Agenten offen dokumentiert und einheitlich nutzbar gemacht werden. Dadurch lassen sich sowohl neue Workflows etablieren als auch bestehende Prozesse effizient replizieren.
Implikationen für KI-Forschung und Industrie
Der offene und systematisierte Ansatz der Nemotron-Terminal-Pipeline ist nicht nur für Forschungsgruppen relevant, sondern eröffnet auch Unternehmen und unabhängigen Entwicklern neue Perspektiven im KI-gestützten Workflow-Design. Insbesondere in Szenarien, wo präzise Interaktion mit Terminal-Umgebungen benötigt wird – zum Beispiel DevOps-Automatisierung, Infrastrukturbewirtschaftung oder automatisierte Fehlerbehebung – profitieren KI-Systeme maßgeblich von strukturiertem und transparentem Trainingsmaterial.
Bisher hat die Zurückhaltung großer Anbieter in puncto Trainingsdaten und -strategien eine breite, unabhängige Weiterentwicklung erschwert. Der Schritt von NVIDIA AI setzt hier einen Impuls für mehr Offenheit und Nachvollziehbarkeit im Bereich der Entwicklung autonomer KI-Agenten.
Transparenz und Technical Standards im Kontext der LLM-basierten Terminal-Agenten
Die zunehmende Verbreitung von KI-Agenten in industriellen und produktiven Arbeitsprozessen macht klar: Langfristig führt kein Weg an branchenweit anerkannten Standards vorbei, was Infrastruktur, Datenqualität und Schnittstellen betrifft. Transparenz in der Datenpipeline ist nicht nur eine technologische, sondern auch eine ethische Frage – sie sorgt für kontrollierbare, auditierbare und reproduzierbare Ergebnisse.
Mit Lösungen wie Nemotron-Terminal entsteht das Fundament für ein Ökosystem, in dem Unternehmen ihre eigenen LLM-Agenten trainieren und passgenau auf spezifische produktive Anforderungen zuschneiden können. Gleichzeitig wird so verhindert, dass die Entwicklung ausschließlich in den Händen weniger Akteure mit proprietärer Datenbasis verbleibt.
Fazit
Die Veröffentlichung von Nemotron-Terminal durch NVIDIA AI markiert einen wichtigen Meilenstein hin zu mehr Transparenz, Effizienz und Systematik beim Engineering von Trainingsdaten für LLM-basierte Terminal-Agenten. In einer Zeit, in der Datenzugang und Standardisierung zentrale Wachstumsfaktoren für KI-Innovationen darstellen, bietet die Pipeline einen relevanten Rahmen für eine schnellere, nachvollziehbare und diversifizierte Entwicklung autonomer Agenten. Für die KI-Community eröffnet dies die Chance, den „Bottleneck“ der Datenknappheit nachhaltig zu überwinden und nächste Generationen von LLM-Agenten zielgerichtet zu skalieren.
Bildquelle: https://www.marktechpost.com/2026/03/10/nvidia-ai-releases-nemotron-terminal-a-systematic-data-engineering-pipeline-for-scaling-llm-terminal-agents/
What do you feel about this post?

Like

Love

Happy

Haha

Sad